
Claude Sonnet 4.6 et son contexte 1M tokens : analyser un projet complet en un seul prompt
Sonnet 4.6 × contexte 1M tokens = audit complet sans découpage
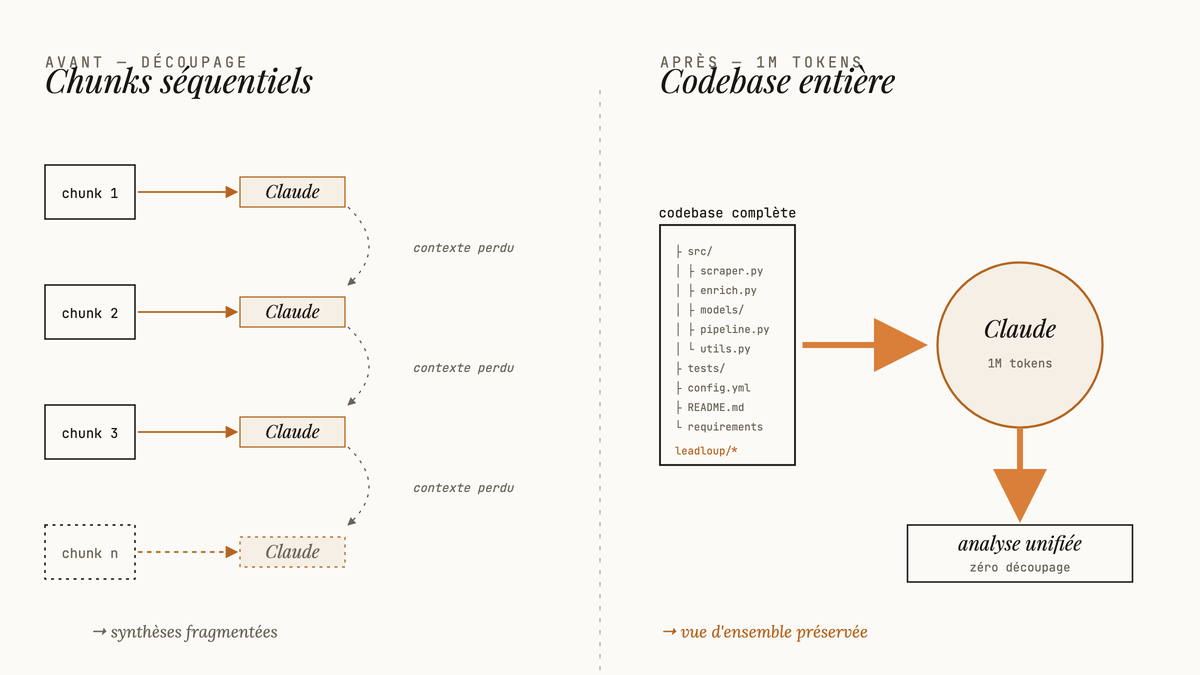
Arrête de découper tes documents en morceaux. Claude Sonnet 4.6 avec son contexte de 1M tokens change vraiment la façon dont tu analyses des projets volumineux. Fini le temps où tu devais passer des heures à segmenter tes PDFs, tes codebases ou tes rapports pour les faire digérer par l’IA.
Aujourd’hui tu vas apprendre à :
- Analyser une codebase complète en un seul prompt sans perdre le contexte global
- Auditer des documents PDF volumineux d’un coup au lieu de les découper
- Optimiser tes prompts pour maximiser l’efficacité du contexte étendu
- Économiser des heures de preprocessing manuel grâce au workflow unifié
- Comparer les performances réelles entre l’approche par chunks et le contexte long
Ce dont t’as besoin avant de commencer
1. Un accès API Anthropic (ou Bedrock/Vertex)
Le contexte 1M tokens pour Sonnet 4.6 passe par l’API Anthropic, Amazon Bedrock ou Google Vertex. Ce n’est pas activé sur la version Pro grand public de claude.ai. Si tu testes juste pour voir, l’API avec quelques dollars de crédit suffit.
2. Ton projet ou document à analyser
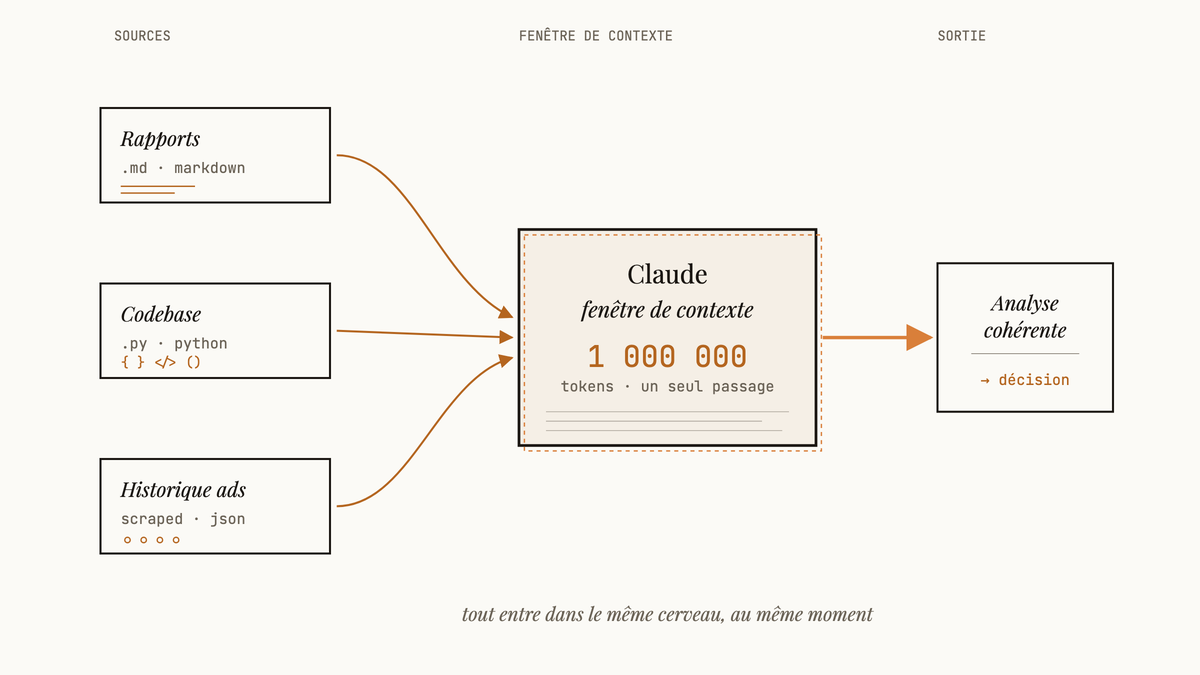
Prépare le contenu que tu veux analyser : codebase complète, rapport PDF de plusieurs centaines de pages, ou documentation technique volumineuse. À titre indicatif, 1M tokens ça encaisse facilement plusieurs centaines de milliers de mots en français, soit plusieurs gros documents combinés.
3. Une stratégie de prompt structurée
Contrairement aux prompts courts habituels, le contexte long nécessite une approche différente. Tu dois structurer ta demande pour guider Claude à travers l’ensemble du contenu.
| Critère | Approche traditionnelle par chunks | Contexte 1M tokens |
|---|---|---|
| Préparation | Découpage manuel en sections de quelques milliers de tokens | Upload direct du document ou collage du contenu entier |
| Analyse | Traitement séquentiel avec risque de perte de contexte entre sections | Compréhension globale, contexte maintenu de bout en bout |
| Temps de setup | 30 minutes à plusieurs heures selon la taille | Quelques minutes |
| Qualité du résultat | Recommandations parfois contradictoires entre chunks | Cohérence sur l'ensemble du projet |
Le workflow, étape par étape
Préparation du contenu source
5 minutes
Pour une codebase, tu peux soit uploader directement les fichiers via l’interface Claude, soit copier-coller le contenu dans l’ordre logique. L’avantage du contexte 1M tokens, c’est que tu n’as plus besoin de hiérarchiser ou de filtrer. Tu peux inclure les tests, la documentation, les configs : tout.
J’ai testé ça récemment avec mon pipeline LeadLoup (Python, plusieurs dizaines de modules d’enrichissement et de scraping). Avant le contexte 1M, j’aurais dû faire un tri drastique et analyser par modules. Maintenant, je balance toute l’arbo plus les fichiers clés d’un coup.
Important
Assure-toi que ton contenu respecte les politiques d’usage d’Anthropic. Pas de données sensibles ou de propriété intellectuelle protégée sans autorisation.Structure ton prompt d'analyse
10 minutes
Le truc avec le contexte long, c’est que tu peux être beaucoup plus spécifique dans tes demandes. Au lieu de dire « analyse ce code », tu peux demander :
▸ Prompt d'analyse de codebase complète
# ANALYSE COMPLÈTE DE PROJET
## CONTEXTE
Tu as accès à l'intégralité de la codebase [nom du projet]. Analyse-la de manière holistique en gardant en tête les interactions entre tous les composants.
## OBJECTIFS D'ANALYSE
1. **Architecture globale** : Identifie les patterns architecturaux, les dépendances critiques et les points de couplage
2. **Qualité du code** : Détecte les code smells, les duplications et les violations de principes SOLID
3. **Performance** : Repère les goulots d'étranglement potentiels et les optimisations possibles
4. **Sécurité** : Identifie les vulnérabilités et les failles de sécurité
5. **Maintenabilité** : Évalue la dette technique et propose des refactorings prioritaires
## FORMAT DE RÉPONSE
- Synthèse exécutive (3-5 points clés)
- Analyse détaillée par domaine
- Recommandations priorisées avec impact estimé
- Exemples de code concrets pour chaque point soulevé
Commence ton analyse maintenant.Lancement de l'analyse complète
2 minutes
Une fois que tu envoies le prompt, Claude va prendre quelques minutes pour traiter l’ensemble. C’est normal : il lit littéralement tout ton projet d’un coup. Pas comme les approches par chunks où tu devais attendre entre chaque section.
Voici à quoi ça ressemble en pratique : un document attaché, ton prompt structuré, et le compteur de tokens qui s’allume pour te montrer combien de contexte tu consommes.
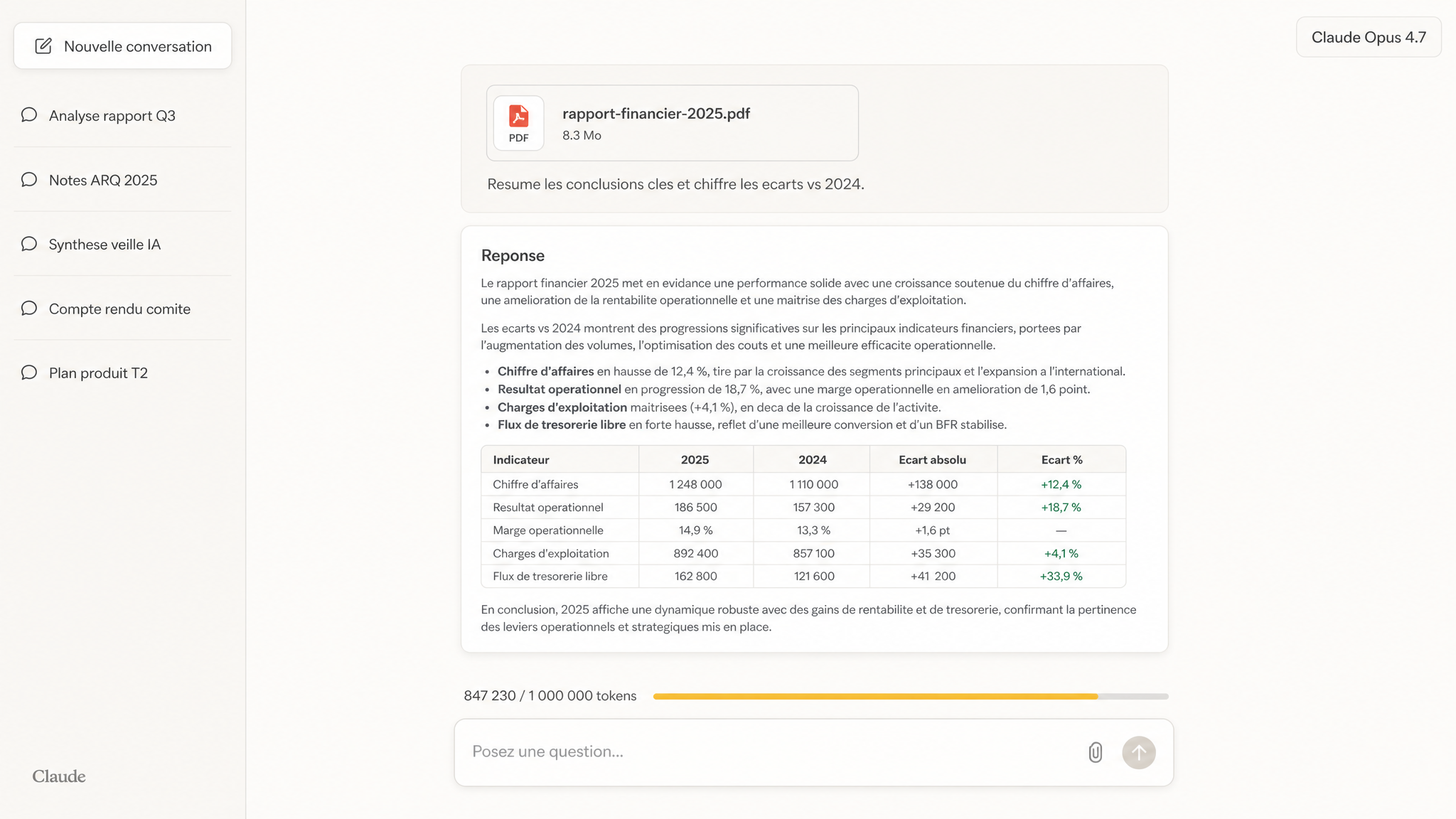 1 2 3
1 2 3 - 1 Fichier PDF attaché
- 2 Tableau comparatif généré
- 3 Compteur de tokens utilisés
Un document attaché, un prompt structuré, et le compteur de tokens qui grimpe en bas du chat.
Le truc impressionnant, c’est que Claude maintient une compréhension cohérente de bout en bout. Il va faire des liens entre une fonction définie au début du prompt et son usage dans un test unitaire collé bien plus loin, sans que tu aies à lui rappeler quoi que ce soit.
Analyse des résultats et questions de suivi
15 minutes
Claude va te sortir une analyse structurée qui couvre tous les aspects de ton projet. Le plus puissant, c’est que tu peux ensuite poser des questions de suivi ultra-précises :
« Montre-moi exactement où mon enrichisseur de leads interagit avec le module Apify, et explique pourquoi le hard cap de coût n’est pas appliqué quand je relance après une erreur. »
Avant le contexte 1M tokens, cette question aurait nécessité plusieurs aller-retours avec des chunks différents. Maintenant, Claude a tout en mémoire et peut répondre avec les noms de fichiers et de fonctions exacts.
Important
Les réponses de Claude peuvent être très longues avec le contexte étendu. Prépare-toi à des analyses de plusieurs milliers de mots.Génération du rapport d'audit
10 minutes
Pour finaliser, tu peux demander à Claude de transformer son analyse en rapport structuré que tu peux envoyer à ton équipe ou à ton client :
▸ Génération de rapport exécutif
Transforme ton analyse en rapport synthétique destiné à ton équipe ou ton client. Structure le rapport ainsi :
## RÉSUMÉ EXÉCUTIF
- État global du projet (note sur 10)
- 3 points forts majeurs
- 3 risques critiques à adresser immédiatement
## RECOMMANDATIONS PRIORITAIRES
Pour chaque recommandation :
- Impact business (Haut/Moyen/Bas)
- Effort de développement estimé (jours-homme)
- ROI attendu
## PLAN D'ACTION 30-60-90 JOURS
Roadmap concrète avec quick wins et projets de fond
## ANNEXES TECHNIQUES
Exemples de code et détails d'implémentation pour l'équipe devTemps pour auditer un projet de plusieurs centaines de fichiers
Ordre de grandeur observé sur mon pipeline LeadLoup. Ton mileage va varier selon la taille et la familiarité du projet.
Quelques trucs bons à savoir
• Coût réel : Sonnet 4.6 à $3 USD / MTok input (~4 $ CAD). Un projet de 500k tokens en entrée coûte environ 2 $ CAD au lieu de dizaines d’heures de travail manuel. Compte un peu plus si tu génères beaucoup d’output (Sonnet est à $15 USD / MTok en sortie).
• Limite de sortie : Sonnet peut générer jusqu’à 64k tokens en output (Opus monte à 128k). Ça représente plusieurs dizaines de milliers de mots, largement suffisant pour un rapport détaillé.
• Performance variable : Plus ton contexte est long, plus Claude prend du temps à répondre. Attends-toi à quelques minutes pour les analyses vraiment volumineuses.
• Qualité du prompt crucial : Avec autant de contexte, un prompt mal structuré peut donner des réponses confuses. Investis du temps dans la préparation de tes instructions.
• Pas de persistence parfaite : Même avec 1M tokens, Claude peut parfois perdre des détails très spécifiques. Garde tes sources organisées pour référence.
• Format d’entrée limité : Tous les formats ne passent pas parfaitement. Les PDFs complexes avec beaucoup de graphiques peuvent poser problème.
Le hic
Soyons clairs : le contexte 1M tokens n’est pas magique.
La vitesse d’analyse reste lente. Pour des projets vraiment volumineux, Claude prend plusieurs minutes à traiter avant même de commencer sa réponse. Si tu es habitué aux réponses instantanées des prompts courts, ça peut frustrer.
Les coûts s’additionnent vite. À $3 USD / MTok input (~4 $ CAD), un projet de 800k tokens te coûte environ 3,30 $ CAD à chaque passe d’analyse. C’est dérisoire pour une analyse, mais si tu itères dix fois sur la même codebase avec des prompts différents, tu montes vite à 30 $ CAD juste pour les inputs. Et l’output (Sonnet à $15 USD / MTok, ~20 $ CAD) ajoute sa propre note quand Claude pond des rapports de 30 000 mots.
La qualité dépend énormément de ton prompt. Avec autant de contexte, un prompt flou va donner des résultats flous. Tu dois être beaucoup plus précis qu’avec les approches traditionnelles. C’est un skill à développer.
Claude peut parfois se perdre dans les détails. Sur de très gros projets, j’ai remarqué qu’il peut sur-analyser certaines sections au détriment de la vue d’ensemble. Tu dois parfois le recadrer.
Pas de mémoire entre sessions. Chaque nouvelle conversation repart de zéro. Si tu veux continuer une analyse, tu dois re-uploader tout le contexte. Ça peut être chiant pour les projets avec beaucoup d’itérations.
| Dimension | Où ça accroche | Impact concret |
|---|---|---|
| Vitesse | Traitement initial | Quelques minutes d'attente incompressibles |
| Coût | Projets volumineux | Budget à prévoir pour les analyses répétées |
| Complexité | Setup du prompt | Courbe d'apprentissage pour structurer tes instructions |
| Mémoire | Sessions multiples | Pas de continuité automatique entre conversations |
Alternatives à considérer
Cursor avec leur analyse de codebase intégrée gère bien l’analyse de projets moyens sans les coûts par token. Par contre, tu restes limité à l’écosystème de développement et tu n’as pas la flexibilité de Claude pour des analyses business ou des documents non-techniques.
NotebookLM de Google excelle pour analyser des documents PDF volumineux et générer des synthèses audio. L’avantage : c’est gratuit et ça gère très bien les sources multiples. L’inconvénient : moins flexible pour le code et les analyses techniques poussées.
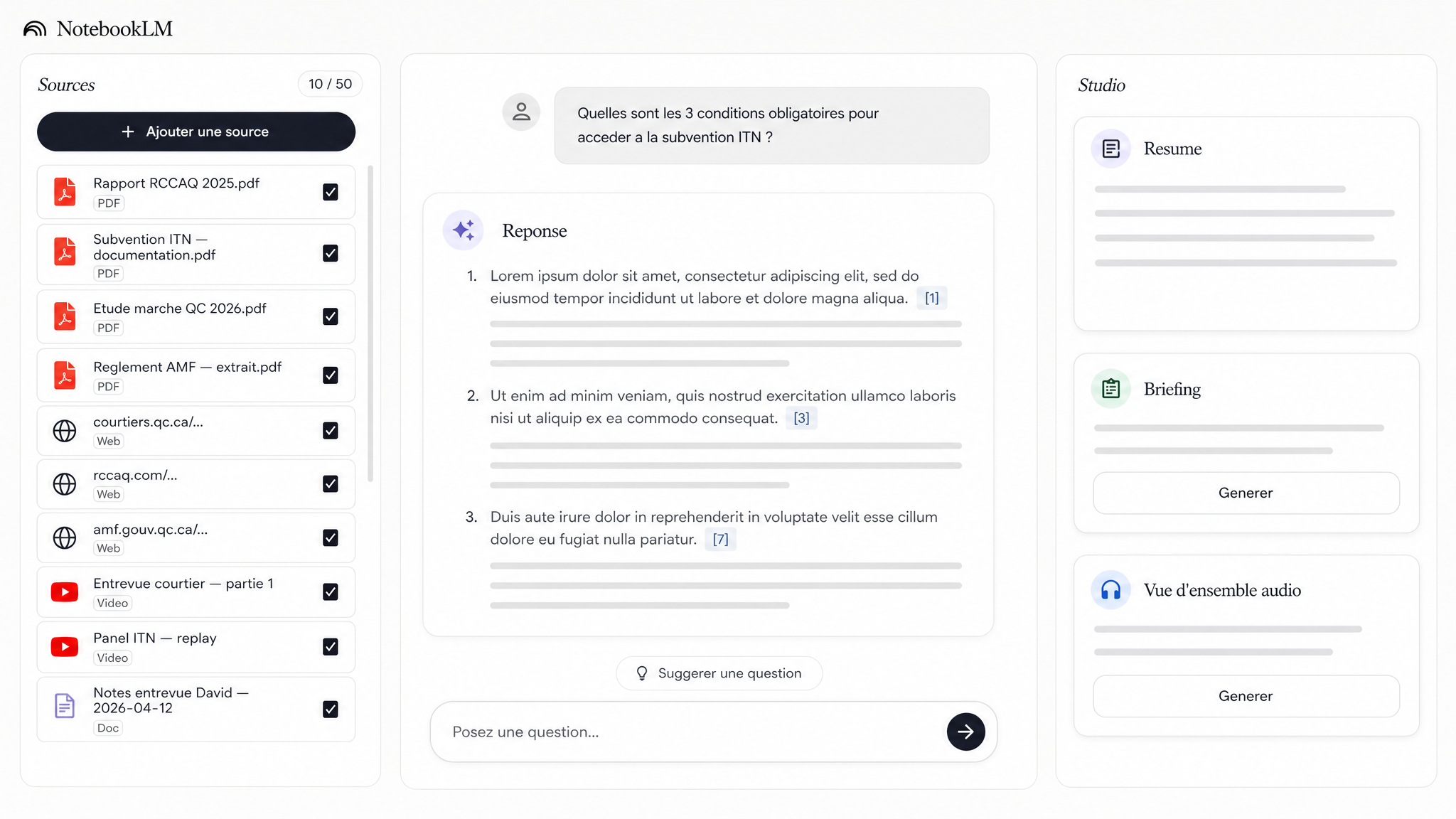 1 2 3
1 2 3 - 1 Bouton Ajouter une source
- 2 Zone de conversation IA
- 3 Vue d'ensemble audio
Interface NotebookLM avec panneau des sources à gauche, zone de conversation au centre et studio à droite pour analyser des documents.
Gemini 2.5 Pro offre aussi un contexte étendu à prix compétitif côté Google. Bon pour la compréhension globale et l’intégration native dans Workspace, généralement moins précis que Sonnet 4.6 pour les recommandations techniques détaillées sur du code. Ça vaut le coup de comparer selon ton type de projet.
La vraie question : est-ce que tu as besoin de la qualité d’analyse supérieure de Claude, ou est-ce qu’une alternative moins chère mais moins précise suffit pour tes besoins ?
Cas d’usage concrets où ça brille (chez moi)
Audit complet du pipeline LeadLoup. Mon pipeline Python qui sort des leads qualifiés pour des cabinets de recrutement spécialisé. Plusieurs dizaines de modules, scripts d’enrichissement, configs Apify, templates HTML d’ads. Avant, je posais des questions à Claude module par module et je perdais le fil des dépendances. Là, je colle l’arbo complète plus les fichiers clés en un prompt, je demande où sont les couplages forts et les zones à refactor. La réponse arrive avec les bons noms de fonctions et les bonnes lignes, pas une réponse générique.
Synthèse de veille du Centre de recherche. Mon Centre de recherche LeadLoup, c’est un dossier de rapports NotebookLM exportés en markdown : niches B2B QC, ICP, benchmarks d’agences. Quand je veux trancher une décision (« est-ce que je pousse sur les courtiers d’assurance ou les avocats d’affaires ? »), je balance les 6-10 rapports pertinents d’un coup. Claude voit les contradictions entre les rapports, hiérarchise les signaux, et je sors avec une vraie position au lieu d’un résumé tiède.
Audit de l’ad scanner avant client. Mon scraper Meta Ad Library plus l’auditeur de comptes. Quand un nouveau prospect rentre dans le pipeline, je peux faire avaler à Claude l’historique scrapé de son compte ads, son site, et ma checklist d’audit interne. Au lieu de checker manuellement 40 critères, j’obtiens un rapport d’audit pré-rempli que je n’ai qu’à finir à la main.
Le pattern commun : dès que tu as besoin de relier plusieurs sources sur un même sujet sans perdre le contexte entre elles, le contexte 1M tokens devient l’outil par défaut.
Techniques d’optimisation avancées
Structuration hiérarchique des prompts. Au lieu d’un prompt monolithique, utilise une structure en sections avec des niveaux de priorité. Claude traite mieux les instructions organisées quand il doit gérer beaucoup de contexte.
Système de tags et références. Quand tu uploades ton code, ajoute des commentaires de navigation comme // SECTION: Authentication ou // TODO-AUDIT: Performance critique. Claude s’en sert comme points de repère dans l’analyse.
Prompts de validation croisée. Après une première analyse, demande à Claude de vérifier ses propres conclusions : « Relis ton analyse et identifie les points où tu pourrais t’être trompé ou avoir manqué des éléments importants. » Ça améliore significativement la qualité.
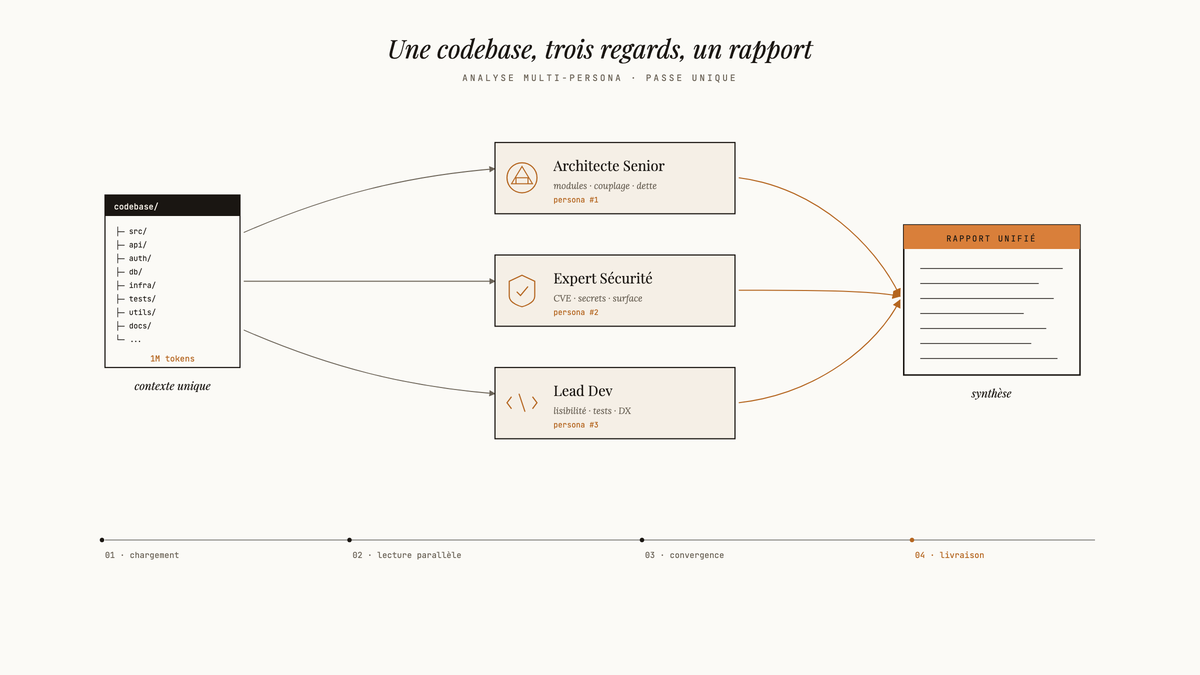
Approche par personas. Structure tes prompts en demandant à Claude d’analyser sous plusieurs angles : « Analyse ce code du point de vue d’un architecte senior, puis d’un expert sécurité, puis d’un développeur junior qui devrait le maintenir. » Tu obtiens des perspectives complémentaires.
▸ Template de prompt optimisé
# ANALYSE MULTI-PERSPECTIVE - [NOM_PROJET]
## CONTEXTE ET CONTRAINTES
- Budget disponible pour corrections : [précise]
- Timeline du projet : [précise]
- Niveau technique de l'équipe : [précise]
## PERSONAS D'ANALYSE
Analyse le projet sous ces 3 angles :
### 1. ARCHITECTE SENIOR
Focus sur : patterns, scalabilité, découplage, dette technique stratégique
### 2. EXPERT SÉCURITÉ
Focus sur : vulnérabilités, exposition des données, authentification, autorisation
### 3. LEAD DÉVELOPPEUR
Focus sur : maintenabilité, testabilité, onboarding nouveaux devs, outils et processus
## FORMAT DE SORTIE
Pour chaque persona :
- Top 3 des préoccupations
- Recommandations avec effort/impact
- Red flags à adresser immédiatement
## VALIDATION
Après analyse, fais une passe de validation croisée entre les 3 perspectives pour identifier les contradictions ou les points manqués.Cette approche multi-perspective avec le contexte 1M tokens te donne une richesse d’analyse difficile à reproduire en collant des chunks séparés.
Retour d’expérience sur mon propre workflow
Depuis que le 1M tokens est dispo sur Sonnet, ma façon de poser des questions à Claude a changé. Avant, je préparais mes prompts comme un sniper : un fichier à la fois, des extraits chirurgicaux. Maintenant je balance et je laisse Claude trier.
Ce qui marche vraiment bien : Les questions transverses sur une codebase moyenne. « Où est-ce que je traite encore mes prospects au lieu de mes leads ? », « Quels modules dépendent encore de l’ancienne version de l’API Meta ? ». Avant, je ne posais même pas ces questions parce que c’était trop long à instrumenter. Là, je les pose et j’obtiens une vraie réponse en quelques minutes.
Où ça brille le plus pour moi : La synthèse multi-sources. Quand je consolide plusieurs deep research NotebookLM en une seule décision business (choix de niche, framing d’offre, séquence d’emails outbound), avoir tous les rapports dans le même prompt me sort des analyses cohérentes au lieu de réponses qui contredisent ce que j’ai dit dans une autre conversation.
Les surprises positives : Claude relève des patterns que je rate. Sur le pipeline LeadLoup, il m’a fait remarquer que j’utilisais trois conventions différentes pour les noms de fonctions d’enrichissement selon les fichiers. Pas critique, mais c’est exactement le genre de chose qu’un humain ne voit plus après six mois sur le même code.
Les limitations à connaître : Sur de très grosses entrées (proche du 1M), Claude se met parfois à survoler certaines sections. Tu sens que la qualité baisse sur les dernières parties du contexte. Pour les analyses vraiment volumineuses, mieux vaut découper en deux passes ciblées plutôt que tout balancer d’un coup.
Le verdict après quelques semaines d’usage régulier : c’est devenu mon mode par défaut pour toute question qui touche plus d’un fichier ou plus d’un document à la fois. Pas magique, mais suffisamment puissant pour que je n’envisage plus de revenir à l’ancien workflow.
Check-list finale
✓ Avant de lancer
Verdict + prochaines étapes
Le contexte 1M tokens de Claude Sonnet 4.6 change réellement la donne pour l’analyse de projets volumineux. C’est l’outil qu’il me fallait pour passer d’analyses partielles à des audits complets et cohérents.
Commence par tester sur un petit projet que tu connais bien pour calibrer tes prompts, puis monte graduellement vers des analyses plus complexes.
Check tes courriels.
Lien à cliquer pour confirmer ton abonnement.
Texte par David Cyr
