
Claude Fable 5 : la revue — le modèle le plus capable d’Anthropic, et ce qu’il refuse de faire
Arrête. Avant de te jeter sur l’API parce que t’as vu passer « le modèle le plus capable jamais sorti », lis ça. Anthropic a lancé Claude Fable 5 le 9 juin 2026, et oui, c’est un vrai cran au-dessus d’Opus. Mais il y a un détail que la moitié des threads excités oublient : Fable 5 va parfois te répondre avec un autre modèle, sans te demander ton avis. Et c’est volontaire.
On a passé l’annonce officielle, le tableau de benchmarks et la doc de sécurité au peigne fin. Voici ce que ça donne, sans le vernis marketing.
Ce qui s’est passé, vraiment
Anthropic n’a pas sorti un modèle. Il en a sorti deux le même jour : Claude Fable 5 et Claude Mythos 5. Et le twist, c’est que c’est le même modèle dessous. La différence est entièrement dans les garde-fous.
Fable 5, c’est la version grand public, disponible partout aujourd’hui via l’API (identifiant claude-fable-5). Mythos 5, c’est exactement la même intelligence mais avec les protections cyber retirées, réservée aux partenaires approuvés — les organisations du Project Glasswing, et bientôt quelques chercheurs en biologie triés sur le volet.
Les deux ouvrent la nouvelle famille Claude 5, un palier que Anthropic appelle « classe Mythos », au-dessus d’Opus dans la hiérarchie. C’est leur façon de dire : ce n’est plus juste un Opus gonflé, c’est l’étage du dessus.
Le truc c’est que cette confiance, elle est chiffrée. Dans les mots d’Anthropic : les capacités de Fable 5 « dépassent celles de tout modèle qu’on a rendu disponible jusqu’ici », et « plus la tâche est longue et complexe, plus l’avance de Fable 5 se creuse ». Traduction : c’est sur les gros mandats agentiques, pas sur les questions rapides, que tu vas sentir la différence.
Les benchmarks officiels, sans filtre
Anthropic a publié son tableau comparatif le jour du lancement. Le voici tel quel — c’est leur capture, pas une reconstitution.
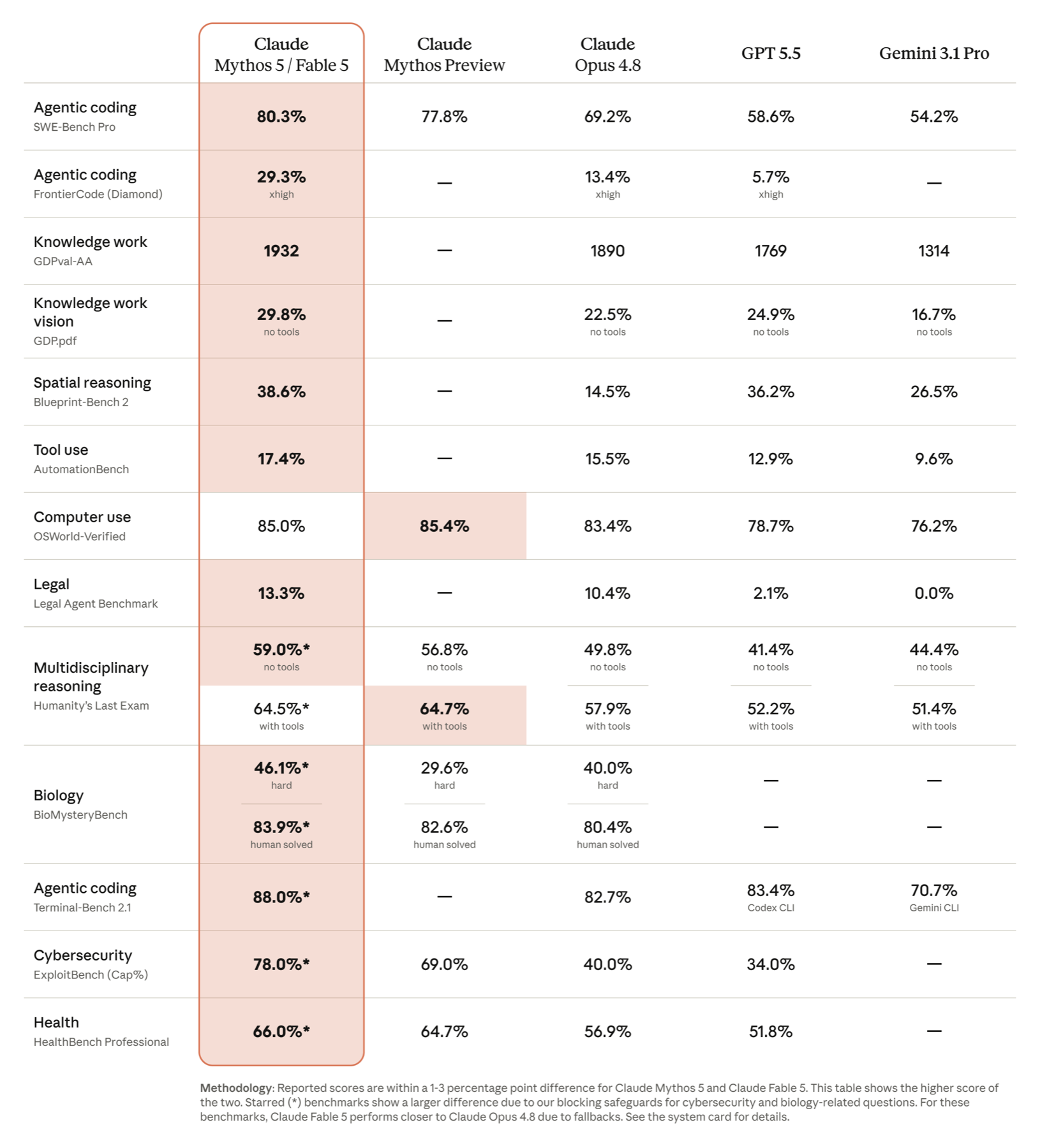
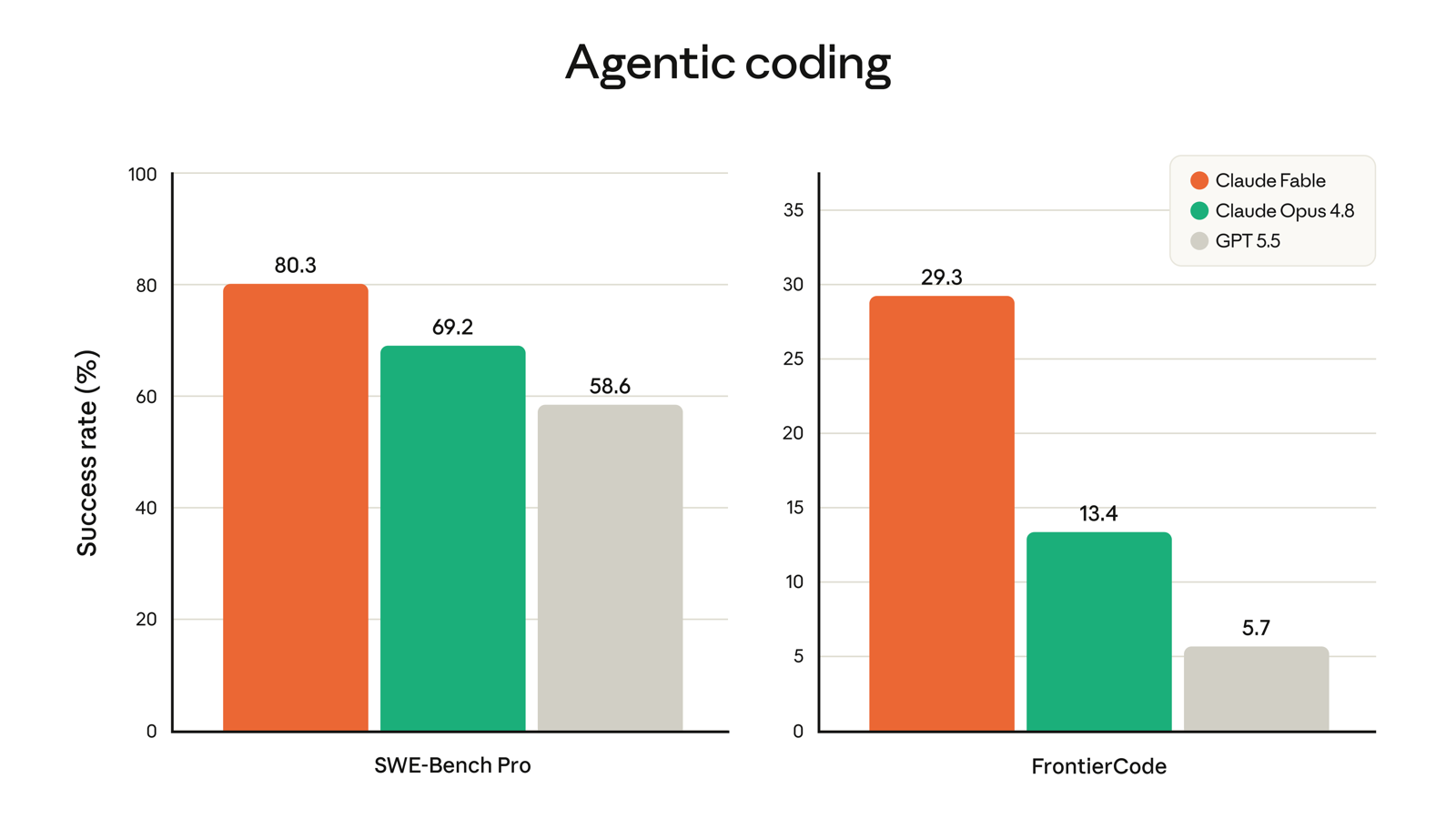
Lis-le côté opérateur, pas concours académique. Le SWE-Bench-Pro : 80,3 % contre 69,2 % pour Opus 4.8. C’est plus de 11 points d’écart sur le benchmark de codage agentique le plus suivi. Sur Humanity’s Last Exam sans outils, c’est 59 % contre 49,8 %. Ces écarts-là, c’est pas du bruit, c’est une génération de différence.
Sur le juridique, le score absolu fait sourire (13,3 %, personne ne brille), mais l’écart avec Gemini 3.1 Pro — qui plafonne à 0,0 % — te dit où en est réellement le marché sur les tâches d’agent légal.
Ce qui change la donne : la vision
Le saut le plus concret, c’est la vision. Anthropic affirme que Fable 5 est le nouvel état de l’art pour tout ce qui touche à l’image : extraire des chiffres précis d’une figure scientifique, reconstruire le code source d’une application web à partir de captures d’écran seules.
La démo qui frappe : les anciens Claude galéraient à jouer à Pokémon FireRed même avec un harnais bourré d’outils d’aide. Fable 5 a fini le jeu avec un harnais minimal, vision pure — juste les images brutes du jeu, sans carte, sans aide à la navigation.
C’est pas un gadget. Si un modèle peut comprendre un écran de jeu sans métadonnées, il peut lire ton interface, ton dashboard, ton PDF mal scanné, ta capture de console — et agir dessus. Pour quiconque construit des agents qui « voient », c’est le déblocage.
Même logique sur le raisonnement physique. Anthropic montre Fable 5 qui construit une simulation du système solaire en dérivant le mouvement orbital des planètes à partir des premiers principes de la physique, puis qui s’en sert pour prédire des éclipses solaires.
Ajoute à ça la fenêtre de contexte d’un million de tokens, la sortie maximale de 128 000 tokens, et le fait qu’Anthropic dit que Fable 5 « travaille en autonomie plus longtemps que tout modèle Claude précédent ». Tu obtiens un modèle taillé pour les mandats que les autres ne peuvent pas tenir d’un bloc : auditer une codebase complète, réviser 400 pages de contrats, faire de la recherche sur un corpus entier.
Le vrai sujet : ce que Fable 5 refuse de faire
Voici la partie que les threads excités sautent. Fable 5 embarque des garde-fous qui changent de modèle dans ton dos.
Quand les classificateurs de Fable détectent une requête liée à la cybersécurité, à la biologie, à la chimie ou à la distillation de modèle, la réponse est automatiquement prise en charge par Claude Opus 4.8 à la place. Tu es informé quand ça arrive. Mais tu as payé pour du Fable, et tu reçois du Opus.
Pourquoi ? Parce qu’un modèle aussi capable, sans garde-fous, pourrait être détourné pour faire de vrais dégâts — une cyberattaque, une menace biologique. Anthropic a choisi de calibrer les protections de façon conservatrice : elles se déclenchent dans moins de 5 % des sessions en moyenne, et attrapent parfois des requêtes parfaitement bénignes.
C’est une décision défendable, et honnêtement saine. Anthropic le dit lui-même : une réponse qui retombe sur Opus 4.8 reste « une bien meilleure expérience qu’un refus pur et simple ». Opus 4.8 n’est pas un lot de consolation — c’est un excellent modèle.
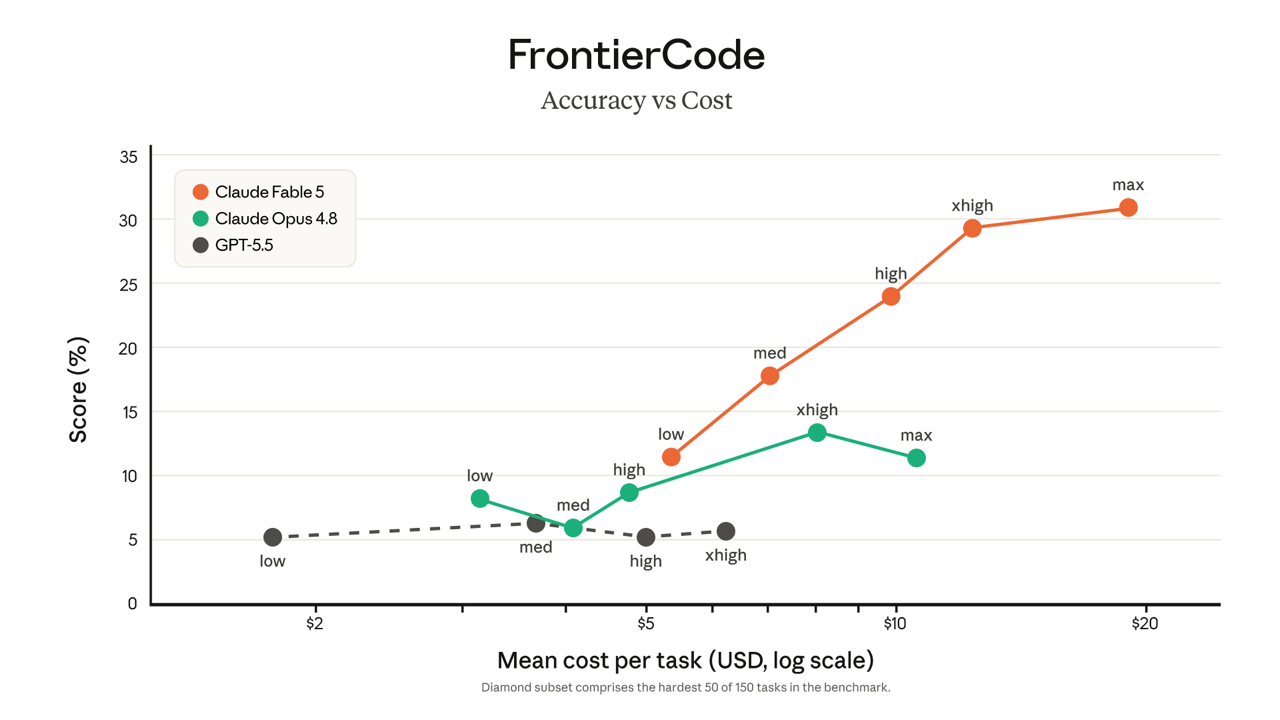
Mais ça a une conséquence directe sur la lecture des benchmarks. Tu te souviens des scores étoilés (*) dans le tableau ? Cybersécurité 78 %, Terminal-Bench 88 %, biologie 83,9 % ? Ce sont les scores de Mythos 5, le jumeau sans garde-fous. Sur ces épreuves précises, Fable 5 — la version que tu utilises — performe plus près d’Opus 4.8, parce qu’il se rabat. La note de méthodologie d’Anthropic le dit noir sur blanc.
Important
Ne lis pas les chiffres étoilés comme les performances de Fable 5 en production. Sur le cyber, la bio et la chimie, le modèle public bascule sur Opus 4.8. Le 78 % en cybersécurité, c’est Mythos 5 — réservé aux partenaires Glasswing. En clair : si ton usage touche la sécurité offensive ou les sciences du vivant, teste avant de bâtir dessus.
Le prix : la grosse pièce, pas le quotidien
À 10 $US (~13,50 $ CAD) en entrée et 50 $US (~67,50 $ CAD) en sortie par million de tokens, Fable 5 coûte le double d’Opus 4.8 sur la sortie (qui est à 5/25 $US). Anthropic présente ça comme une baisse — et ça l’est, par rapport à Mythos Preview, à plus du double. Mais en absolu, ça reste du premium.
Fais le calcul à l’envers. Une analyse qui avale 800 000 tokens en entrée et en recrache 35 000, ça te coûte autour de 10 $US (~13,50 $ CAD) la passe. Ponctuellement, sur un audit qui te ferait économiser une journée de travail, c’est une aubaine. En boucle quotidienne dans une app de prod, ça chiffre vite. C’est le cœur de la décision : Fable 5 est rentable quand ton temps — ou celui que tu factures — vaut nettement plus que la facture API.
Où ça pèche
Trois angles morts à connaître avant de t’engager.
1. Le basculement silencieux est imprévisible. Pour la plupart des gens, les 5 % de faux positifs ne se verront jamais. Mais si tu bâtis un outil de pentest, d’analyse de malware ou de recherche biomédicale, tu vas frapper le mur des classificateurs — et ton « modèle le plus capable » se transformera en Opus 4.8 sans prévenir. Anthropic promet de réduire les faux positifs après le lancement, mais pour l’instant, c’est calibré serré.
2. La disponibilité est échelonnée. Fable 5 est pleinement dispo aujourd’hui sur l’API et les plans Enterprise à la consommation. Sur les abonnements grand public, le déploiement se fait en étapes, plus prudemment, parce qu’Anthropic s’attend à une demande « très forte et difficile à prédire ». Mythos 5, lui, reste verrouillé aux partenaires Glasswing et à quelques chercheurs en biologie.
3. Le premium n’a de sens que sur le volume. Sur les benchmarks académiques classiques, l’écart avec Opus 4.8 est réel mais pas spectaculaire pour une question simple. Les gains éclatent sur les tâches longues, agentiques, multi-étapes. Si ton workflow, c’est du prototypage rapide et des questions courtes, tu paies une capacité que tu n’exploites pas.
Pour qui, et contre quoi
Face à GPT 5.5 et Gemini 3.1 Pro, le tableau officiel donne l’avantage à Fable 5 sur quasiment toutes les épreuves de codage, de vision et de raisonnement. Gemini 3.1 Pro garde son argument de contexte massif annoncé, mais sur la cohérence des tâches longues, c’est Fable 5 qui tient la corde dans les chiffres d’Anthropic.
Le vrai concurrent de Fable 5, ce n’est pas la rue d’en face. C’est Opus 4.8, dans la même maison, à moitié prix sur la sortie. Pour une bonne partie des mandats, Opus suffit largement — et c’est littéralement ce que Fable te sert quand ses garde-fous se déclenchent.
L’essayer
Tu veux le contexte complet sur la gamme — Sonnet, Opus, Haiku, et où chaque modèle est rentable ? On tient la fiche Claude à jour à chaque release, prix vérifiés à la main.
Le verdict final
Fable 5 fait ce qu’Anthropic promet : c’est le Claude le plus fort, et sur le codage agentique et la vision, l’avance est nette et chiffrée. Pas du marketing — des benchmarks publics, vérifiables, qu’on a mis côte à côte plus haut.
Mais la vraie histoire de ce lancement, c’est pas la puissance. C’est le compromis. Anthropic a choisi de sortir un modèle plus capable que tout ce qui existe en bridant volontairement ce qu’il accepte de faire, et en te le disant ouvertement. Tu paies le prix de la pleine puissance, tu obtiens 95 % de pleine puissance, et 5 % de garde-fou qui te renvoie un cran en dessous. Pour la plupart d’entre nous, c’est invisible. Pour ceux qui touchent au cyber ou à la bio, c’est le détail qui change tout.
Le calcul est simple : Fable 5, c’est l’outil que tu sors quand rien d’autre ne fait la job, pas ton modèle par défaut. Garde Sonnet pour le quotidien, Opus pour le raisonnement profond, et réserve Fable aux mandats où un seul passage propre vaut plus que la facture.
Teste-le sur ta vraie tâche avant de bâtir dessus. C’est tout.
Check tes courriels.
Lien à cliquer pour confirmer ton abonnement.
Texte par David Cyr
